This is an article about using Roslyn Workspaces to run quick one-off analysis on your .NET projects without going into complexities of analyzers and code-fixes. It builds upon part 1, where we created a query that analyzed logical expressions inside our code-base. This time we will use Workspaces to replace invocations of an obsolete method with a newer version.
Our synthetic code-base emulates a reporting system for a big corporation. The system pulls together information form accounting, HR, sales and supply systems and prepares analytical reports for our users. It's a big system that has been around for over a decade, so there is quite a bit of legacy code in it. Today we finally decided to get rid of the obsolete overload of our most called method ScheduleReport. We want to replace:
var scheduleId =
reportSchedulingSystem.ScheduleReport(reportName, false, id, null, null, null);
with
var scheduleId =
reportSchedulingSystem.ScheduleReport(
reportName,
new UserIdsAcrossSystems(userIdInAccountingSystem: id),
false).id;
in a fully automated manner.
Roslyn compiler platform is among the best things that happened to .NET in the previous decade. 10 years ago static code analysis was reserved for teams of highly dedicated programmers who spent hundreds of hours studying C# compilation process and intermediary models that stood between a programs text and resulting byte-code. Thanks to their contribution and great work done by the .NET team, today we can achieve the same result in mere hours with a comprehensive and user-friendly API gateway into the compilation process. This article will show you the easiest, yet very practical form of static code analysis with Roslyn, something that takes under an hour to use: Workspaces.
Roslyn is at the core of modern C# IDEs. When you click a screwdriver icon in Visual Studio and choose a quick refactoring - that's a Roslyn "code fix". When during compilation a 3-rd party library gives you a warning concerning how your code is using its API - that's Roslyn "analyzer".
There have been ample articles written about analyzers, including my own series 1↗ 2↗ 3↗ 4↗. But analyzers are not something that a typical dev gets to write often. They are mostly handled by teams maintaining libraries and frameworks. In day-to-day application development there isn't much opportunity to write them, nor is there budget to get through initial learning overhead. On the other hand, a typical enterprise developer routinely does refactoring work, analyzing various pieces of code in a big code-base, looking for spots that can be unified and improved. That's where Workspaces and one-off refactoring come in. One-off refactoring is much easier than writing an analyzer, since we don't have to worry about code efficiency and dozens of corner-cases that an analyzer has to account for. And with the relatively small amount of effort needed to get comfortable with such refactoring - it becomes a net positive time saved very quickly.
Working on Roslyn extensions is a bit different from day-to-day enterprise development. You have to get used to working with immutable trees of data representing everything in a solution. You also have to keep in your head, which parts of code map to nodes, which to tokens and other code tree representation subtleties. This article will teach you a few things to get results faster and alleviate the tedium.
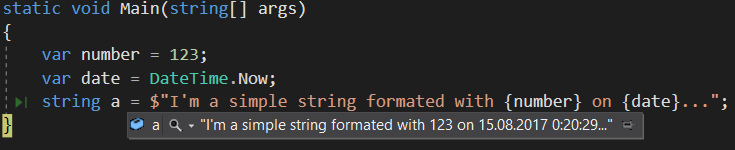
One of the best new features of C# 6 was string interpolation. It is much nicer to read, and you no longer had to rely on 3rd party libraries remembering to introduce ‘DoSomethingFormat(string, params object[])’ along with just ‘DoSomething(string)’.
But ‘DoSomethingFormat’ has one big advantage over string interpolation when it came to unit tests – you can assert on particular values direcly, without having to parse them out of an applied string template. If your date or number format suddenly changes, you don’t need to change your Unit Tests (provided, of course, the format itself is not important enough, just the data).
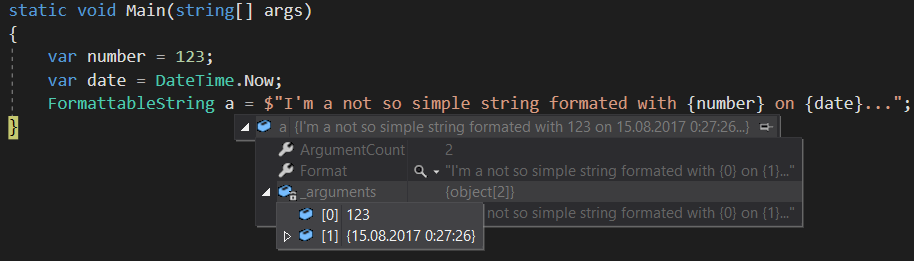
Well, good news – interpolated strings have a rarely mentioned way for you to have the best of both worlds - FormattableString type!
In the previous article we looked at the result of parsing stage of compilation - syntax graph, how it represent information available to C# compiler from analyzing a single file of code and, consequentially, reflects that text quite faithfully and how to transform it to refactor existing code. In this article we will look at symbol graph - result of the next stage of compilation - binding.
In the syntax graph you can see that core C# concepts are represented by corresponding node type, like ClassDeclaration or MethodDeclaration. Inside they often contain IdentifierTokens representing the textual name of some type, but that is as much information as you initially get. In order to get information about a particular type, like its namespace or members, you’d need to get its symbol by performing a costly binding process – check which namespaces are currently used in the file, look for type declarations through the entire solution and all imported DLLs that match, compile them if need be, etc. - compile everything.
The symbol graph allows you to answer a lot more meaningful questions than syntax graph. Want to track down all usages of a specific type? Rename something solution-wide? You can do that.
You can trigger a limited binding for a given piece of syntax graph, or you can hook into the compilation process of the IDE itself (it is continuously recompiling your solution on every change to warn you of any errors as you type away). This common way to do this is by creating a class inheriting from DiagnosticAnalyzer.
From the point of view of developer using it (we will call them 'user-dev'), Refactorings in Roslyn are additional commands that pop-up in Visual Studio when they click certain pieces of code. From our point of view, Refactorings are classes inheriting from CodeRefactoringProvider, which get a chance to examine current syntax graph every time user-dev clicks something in it and determine, if they should offer any transformations of that graph based on its state and what was clicked.
We will be building a Refactoring which allows our user-dev to regenerate a given classes public constructor by adding to it any missing assignment of members that match a certain pattern and are not yet assigned during construction. Specifically, this is the refactoring we use at work to regenerate dependency injected constructors.
.NET Compiler Platform, better known as Roslyn, has been one of the best things that happened to C#. In short, it is a compiler made with IDE integration and extensibility in mind. It provides us with hooks to add our own analysis and transformations to the process of compilation. Why is that important? If there was ever a coding rule specific to just one of your projects, that you had to inforce with lots of discipline and diligence, but would rather rely on the compiler for it, or a routine operation you could easily automate if only you could write an IDE extension – Roslyn will make this a reality. It allows you to write code, C# code in my case, that will run as a Visual Studio extension, analyze the code other devs are working on and help them modify it.
Unfortunately, despite initially releasing with Visual Studio 2015, there is still lack of tutorials teaching how to do things beyond ‘Hello world’. For serious development, the best way to learn is to read official documentation wiki and study other prjects available on github - quite a lot of overhead, even if Roslyn is worth it. This series will provide with a more streamlined roadmap - enough knowledge to do useful things and guidelines for farther research. Through the series we will build a refactoring extension for Visual Studio and a simplistic analyzer dll to include into a project. Both small enough to comprehend in an hour, yet performing useful work, solving a task the likes of which you may expect to want to automate yourself in your project. As well as techncial infromation, which can be quite overwhelming at first site, I will try to give hints on the general flow of Rolsyn development: how to decide where to start, how to deal with roadblocks, how to concentrate on important things first.
In part 1 we learned that you can swap parts of an Expression Tree to another compatible (i.e. with a matching return type) expression. Swapping is, in fact, the easiest thing to do - with a bit more work we can construct a serializable representation of almost any bit of C# code. This opens great avenues for Domain Driven Development and introducing hot-swappable, dynamic, yet safe parts of logic to your application.
One of the best examples of the power we get is shown by introducing a reusable expression function with LINQKit.
internal static class AddressSubqueries
{
internal static Expression<Func<string, string, string>> FormatCityAndProvince =
(city, province) => "The glorious city of " + city
+ " of the wonderful province of " + province;
}
//used like this:
public IQueryable<string> GetStandardAddressDescription(int addressId)
{
return DataContext
.Addresses.AsExpandable() // this hooks in LINQKit
.Where(x => x.AddressId == addressId)
.Join(
DataContext.StateProvinces,
adr => adr.StateProvinceId,
prov => prov.StateProvinceId,
(adr, prov) => AddressSubqueries.
FormatCityAndProvince // <==
.Invoke(adr.City, prov.Name))
.FirstOrDefault();
}
In the previous part we have determined that:
- IQueryably consists of a Provider and an Expression Tree
- Expression Trees can be combined almost as easily as pieces of C# code
In this article, we will look at treating our queries are reusable chunks of logic and combining them into more complex yet still readable queries like this:
public IQueryable<ProductModelOrderStatisticsDto> GetProductModelOrderStats()
{
// a bigger, more detailed query
IQueryable<WorkOrderSummaryDto> allDurationsAndRoutings =
GetWorkOrderSummaries();
// is wrapped by an aggregation to retrieve statistics
var averagePerModel = allDurationsAndRoutings
.GroupBy(x => new { x.ProductModelId, x.ModelName })
.Select(x => new ProductModelOrderStatisticsDto
{
ModelId = x.Key.ProductModelId,
ModelName = x.Key.ModelName,
AverageDuration = x.Where(y => y.DurationDays.HasValue)
.Average(y => y.DurationDays.Value),
AverageRoutings = x.Average(y => y.RoutingsCount)
});
return averagePerModel;
}Many .NET developers don’t realize or don’t pay attention to the differences between IEnumerable and IQueryable. Most tutorials on the topic don’t go beyond trivial examples, thus missing the huge potential hidden inside.
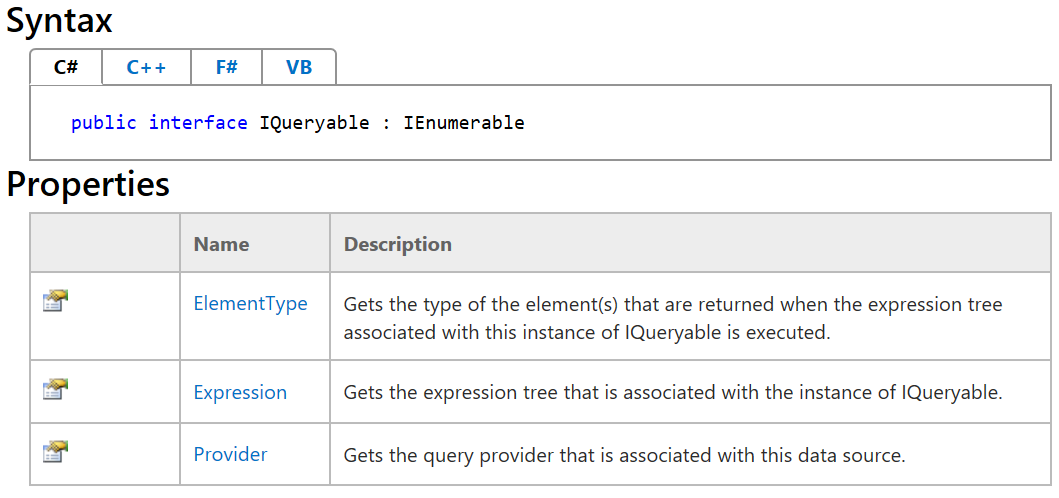
IQueryable is IEnumerable and much more.
