Part 1 -
Important concepts and development setup
Part 2 -
Visual Studio extension for refactoring
Project used in this article is available on
GitHub
In the previous article we looked at the result of parsing stage of compilation - syntax graph, how it represent information available to C# compiler from analyzing a single file of code and, consequentially, reflects that text quite faithfully and how to transform it to refactor existing code. In this article we will look at symbol graph - result of the next stage of compilation - binding.
In the syntax graph you can see that core C# concepts are represented by corresponding node type, like ClassDeclaration or MethodDeclaration . Inside they often contain IdentifierTokens representing the textual name of some type, but that is as much information as you initially get. In order to get information about a particular type, like its namespace or members, you’d need to get its symbol by performing a costly binding process – check which namespaces are currently used in the file, look for type declarations through the entire solution and all imported DLLs that match, compile them if need be, etc. - compile everything.
The symbol graph allows you to answer a lot more meaningful questions than syntax graph. Want to track down all usages of a specific type? Rename something solution-wide? You can do that.
You can trigger a limited binding for a given piece of syntax graph, or you can hook into the compilation process of the IDE itself (it is continuously recompiling your solution on every change to warn you of any errors as you type away). This common way to do this is by creating a class inheriting from DiagnosticAnalyzer.
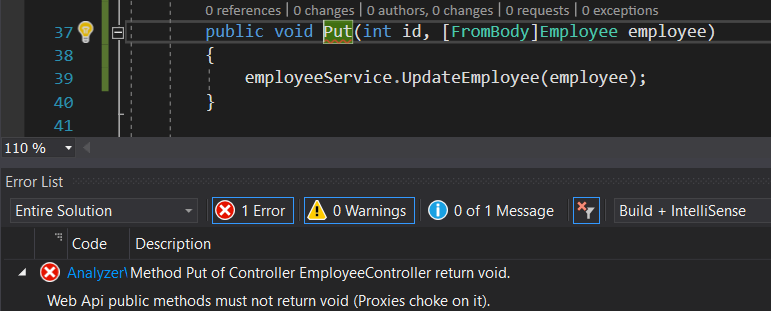
Once again, I will be solving a problem from my daily practice. Due to some proxy misconfiguration, Web API methods in our applications must not return void, since that will cause http request to never finish in the browser. We have a simple unit test which reflects upon every WebApi controller method and makes sure they don’t return void. However, our test suit is huge, so it only runs on integration server. We could save some 30 minutes a few times per week, if notified all our developers working on a specific project about this issue and offered a fix right away. That’s what we are going to do.
Step 1 - Project creation
We start by creating an Analyzer with Code Fox project from the template. It already comes with testing infrastructure.
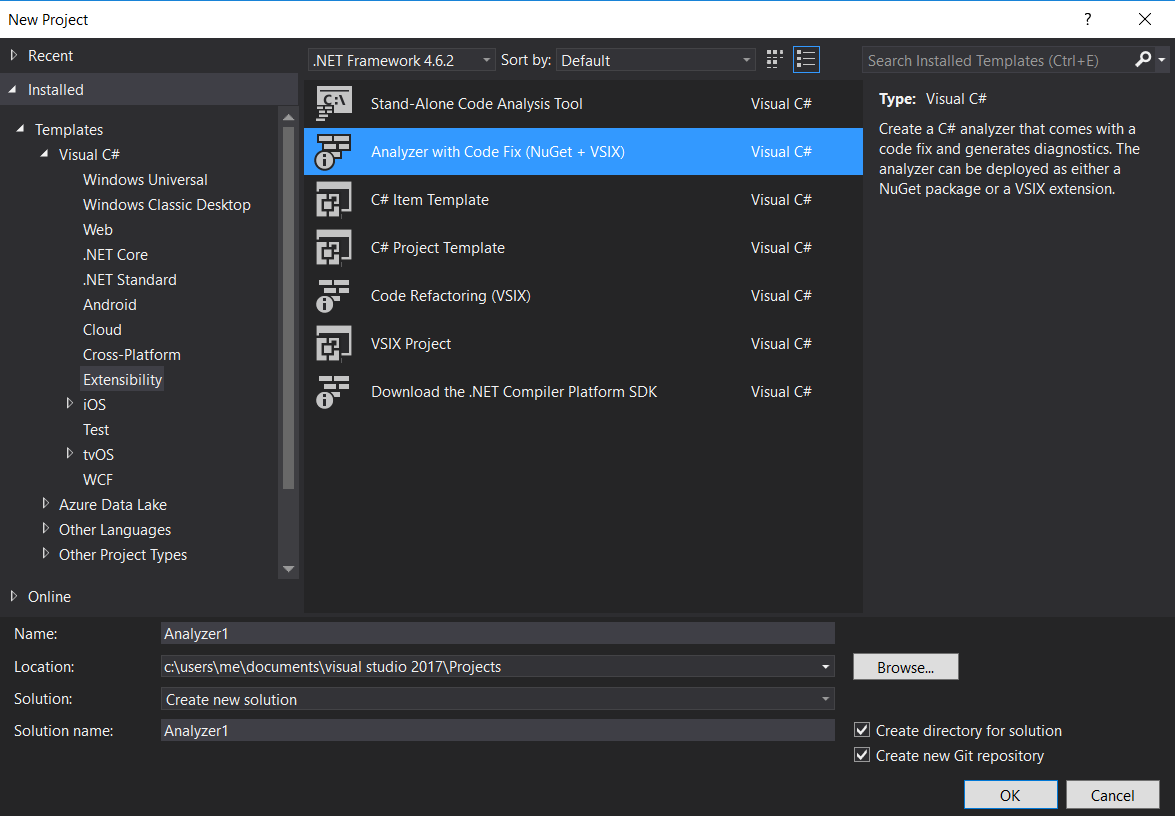
First thing we do is fill up the boilerplate and text message that our analyzer will use. Not much to say here.
[DiagnosticAnalyzer(LanguageNames.CSharp)]
public class AnalyzerWebApiNoVoidReturnAnalyzer : DiagnosticAnalyzer
{
public const string DiagnosticId = "AnalyzerWebApiNoVoidReturn";
public static readonly string Title =
"Web Api public method return void.";
public static readonly string MessageFormat =
"Method {1} of Controller {0} return void.";
public static readonly string Description =
"Web Api public methods must not " +
"return void (Proxies choke on it).";
private const string Category = "Naming";
private static DiagnosticDescriptor Rule =
new DiagnosticDescriptor(DiagnosticId,
Title,
MessageFormat,
Category,
DiagnosticSeverity.Error,
isEnabledByDefault: true,
description: Description);
public override ImmutableArray<DiagnosticDescriptor>
SupportedDiagnostics
=> ImmutableArray.Create(Rule);
Step 2 - What Symobl to analyze?
The first decision you need to make when building an analyzer – what Symbol Kind we want to analyze. In our case, this can either be MethodSymbol or TypeSymbol. I tend to go for simplicity. Analyzing type would involve getting a collection of its methods, filtering and then fixing them. Analyzing a method only involves checking its own properties and its parent type inheritance – much simpler.
public override void Initialize(AnalysisContext context)
{
// we want to act on 'MethodSymbols'
context.RegisterSymbolAction(AnalyzeSymbol, SymbolKind.Method);
}
private static void AnalyzeSymbol(SymbolAnalysisContext context)
{
var namedMethodSymbol = (IMethodSymbol)context.Symbol;
// we filter out methods which are of no itnerest to us,
// starting with properties cheapest to check
// only methods that are part of an API will be public on a contoller
if (namedMethodSymbol.DeclaredAccessibility != Accessibility.Public)
{
return;
}
// return type must be void
if (namedMethodSymbol.ReturnsVoid != true)
{
return;
}
// i'd estimate only 5% of methods
// will pass filters above,
// now we can do more expensive check
var namedTypeSymbol = namedMethodSymbol.ContainingType;
// Surprise! Constructors may look like they return
// a new instance, but they actually have a return
// type of void, we need to check for them
var constructors = namedTypeSymbol.Constructors;
if (constructors.Contains(namedMethodSymbol))
{
return;
}
// the symbol which we want to check in the inheritance chain
// of the class declaring our method
var webApiControllerTypeSymbol =
context.Compilation.GetTypeByMetadataName(
"System.Web.Http.ApiController");
// custom extension, see below
var isInheritingWebApiController =
namedTypeSymbol.IsInheritingFrom(webApiControllerTypeSymbol);
if (isInheritingWebApiController == false)
{
return;
}
// For all such symbols, produce a diagnostic.
var diagnostic = Diagnostic.Create(
Rule,
namedMethodSymbol.Locations[0],
namedTypeSymbol.Name,
namedMethodSymbol.Name);
// there, now our user-dev will immediately be notified
context.ReportDiagnostic(diagnostic);
}
public static bool IsInheritingFrom(
this INamedTypeSymbol typeInheriting,
INamedTypeSymbol typeInherited)
{
if(typeInheriting == typeInherited)
{
return true;
}
var currentyType = typeInheriting.BaseType;
while(currentyType != null)
{
if (currentyType == typeInherited)
{
return true;
}
currentyType = currentyType.BaseType;
}
return false;
}
And that’s it. This is enough to tell the compiler "such method signature is an error". Took us less than 10 minutes to write and saved them back on the first week.
Can we do even more? Yes. We can also offer our user-dev a one-click fix. That is a job of CodeFixProvider.
Step 3 - Provide a fix
Since we will be fixing program text, we will have to go back to Syntax Graph to produce a fix.
[ExportCodeFixProvider(LanguageNames.CSharp, Name = nameof(AnalyzerWebApiNoVoidReturnCodeFixProvider)), Shared]
public class AnalyzerWebApiNoVoidReturnCodeFixProvider : CodeFixProvider
{
private const string title = "Return random int";
// link our fix with analyzer
public sealed override ImmutableArray FixableDiagnosticIds =>
ImmutableArray.Create(AnalyzerWebApiNoVoidReturnAnalyzer.DiagnosticId);
public sealed override FixAllProvider GetFixAllProvider()
{
// See
// https://github.com/dotnet/roslyn/blob/master/docs/analyzers/FixAllProvider.md
// for more information on Fix All Providers
return WellKnownFixAllProviders.BatchFixer;
}
// registration boilerplate
public sealed override async Task RegisterCodeFixesAsync(CodeFixContext context)
{
var root = await context.Document
.GetSyntaxRootAsync(context.CancellationToken)
.ConfigureAwait(false);
var diagnostic = context.Diagnostics.First();
var diagnosticSpan = diagnostic.Location.SourceSpan;
var declaration = root.FindToken(diagnosticSpan.Start)
.Parent.AncestorsAndSelf()
.OfType().First();
context.RegisterCodeFix(
CodeAction.Create(
title: title,
createChangedSolution: c =>
SwitchReturnToRandomInt(context.Document, declaration, c),
equivalenceKey: title),
diagnostic);
}
// syntax graph representing 'return new Random().Next();'
// remember Roslyn quoter from part 2?
private static ReturnStatementSyntax ReturnRandomIntSyntax =
SF.ReturnStatement(
SF.InvocationExpression(
SF.MemberAccessExpression(
SyntaxKind.SimpleMemberAccessExpression,
SF.ObjectCreationExpression(
SF.IdentifierName("Random"))
.WithArgumentList(
SF.ArgumentList()),
SF.IdentifierName("Next"))));
// method which takes care of returns,
// this manipulation should be familliar to you from part 2
private async Task<Solution> SwitchReturnToRandomInt(
Document document,
MethodDeclarationSyntax methodDecl,
CancellationToken cancellationToken)
{
var newBody = methodDecl.Body;
var newBodyStatements = newBody.ChildNodes().ToArray();
// remember, void methods end with an implicit 'return;',
// but methods returning 'int' need an explicit return,
// so we should add it as last statement.
// To avoid duplication code as much as possible,
// we check if there is an obvious return at the end.
// This may sometimes cause unreachable code, but more on that later.
// Notice, newBodyStatements is composed of 'Child' nodes,
// not 'Descendant'.
var endsWithReturn = newBodyStatements.LastOrDefault()
is ReturnStatementSyntax;
if (endsWithReturn == false)
{
newBodyStatements = newBody
.ChildNodes()
.Concat(new[] { SF.ReturnStatement() })
.ToArray();
newBody = newBody.WithStatements(SF.List(newBodyStatements));
}
var returns = newBody.DescendantNodes()
.OfType<ReturnStatementSyntax>()
.ToArray();
// replace every existing return statement
// with return of random int
newBody = newBody.ReplaceNodes(returns, (original, updated) =>
{
return ReturnRandomIntSyntax
.WithLeadingTrivia(original.GetLeadingTrivia())
.WithTrailingTrivia(original.GetTrailingTrivia());
});
// replace return type of the method
var intTypeSyntax = SF.PredefinedType(
SF.Token(SyntaxKind.IntKeyword));
var newMethodDecl = methodDecl
.WithReturnType(intTypeSyntax)
.WithBody(newBody);
var oldClass = (ClassDeclarationSyntax)methodDecl.Parent;
// replace method in class
var newClass = oldClass.ReplaceNode(methodDecl, newMethodDecl);
// replace class
var newRoot = (await document.GetSyntaxRootAsync())
.ReplaceNode(oldClass, newClass);
// this is new - you have to also
// replace the document in solution
var newSolution = document.Project.Solution
.RemoveDocument(document.Id)
.AddDocument(
document.Id,
document.Name,
newRoot);
return newSolution;
}
}
Now our user-dev can fix the problem in one click.
Step 0 - Write tests
As with refactoring, the best way to develop fixes is with Test Driven Development.
[TestMethod]
public void OnClassInheritingWebApiCtrlWithViolationMethodGivesDiag()
{
var test = @"
using System;
using System.Web.Http;
namespace Test
{
public class FooBar: ApiController
{
public void ViolatingMethod()
{
}
}
}";
var expected = new DiagnosticResult
{
Id = "AnalyzerWebApiNoVoidReturn",
Message = String.Format(
AnalyzerWebApiNoVoidReturnAnalyzer.MessageFormat,
"FooBar",
"ViolatingMethod"),
Severity = DiagnosticSeverity.Error,
Locations =
new[] {
new DiagnosticResultLocation("Test0.cs", 9, 21)
}
};
// Check that we get right diagnostics
VerifyCSharpDiagnostic(test, expected);
var fixtest = @"
using System;
using System.Web.Http;
namespace Test
{
public class FooBar: ApiController
{
public int ViolatingMethod()
{
return new Random().Next();
}
}
}";
// check that fix works
VerifyCSharpFix(test, fixtest);
}
A word on fix verification. By default, the VerifyCSharpFix method expects the code to be clean after fix. That is, it will fail assertion if a new diagnostics is found post-fix. And compiler diagnostics include things like unreachable code.
Code in the test below will receive such an error. Because its last return statement is nested in a block of code, it is not part of direct child nodes of our method. The problem here – I’m yet to find a cheap way to detect such code after fix. Ultimately, I don’t think spending time to detect such case is a justified time investment. It will not bring problems, because compiler will detect it and give a new error, which the user-dev will immediately fix. Bottom-line – this would save 30 seconds at best, but would probably take hours for even a partial solution. In order to instruct our assertion to ignore new diagnostics, we need to pass a corresponding parameter allowNewCompilerDiagnostics: true.
[TestMethod]
public void WhenFixingMayAddExtraUnnededReturn()
{
var test = @"
using System;
using System.Web.Http;
namespace Test
{
public class FooBar: ApiController
{
public void ViolatingMethod(int a)
{
if(a > 0)
{
return;
}
else
{
return;
}
}
}
}";
// create and verify expected diagnostics
// VerifyCSharpDiagnostic(test, expected);
var fixtest = @"
using System;
using System.Web.Http;
namespace Test
{
public class FooBar: ApiController
{
public int ViolatingMethod(int a)
{
if(a > 0)
{
return new Random().Next();
}
else
{
return new Random().Next();
}
return new Random().Next();
}
}
}";
// force ignore new diagnostics during verification
VerifyCSharpFix(test, fixtest, allowNewCompilerDiagnostics: true);
}
Step 4 - choosing scope of usage
The next big decision about your analyzer is how you want to use it. Analyzers tend to reflect syntax rules, technical rules or business rules. All of those rules tend to have a scope. For example, syntax rules usually apply to the whole organization, or at least a big subset. You may have a technical rule, which a few teams or even individuals want to follow, but others don’t agree. You can have specific solutions (as in .sln) that should have specific rules apply only to them. Finally, a reusable library package may have a set of rules attached, that should be followed strictly in ever project (as in .csproj) using it, and should be installed in a bundle with it when pooling from Nuget. You can do all of those.
Option 1 is to use a .vsix file provided by a corresponding project added by the template. This will allow you to install your diagnostics into instances of Visual Studio. This is suitable when they should be used by all individuals in scope X, where X may be organization, department or just you personally.
Option 2 is via a nuget package. The template project contains a readymade .nuspec file, which you should edit slightly with any notepad and two files install.ps1 and uninstall.ps1, which will hook the analyzer from the nuget package made by that nuspec into the build process of every project where this analyzer is added.
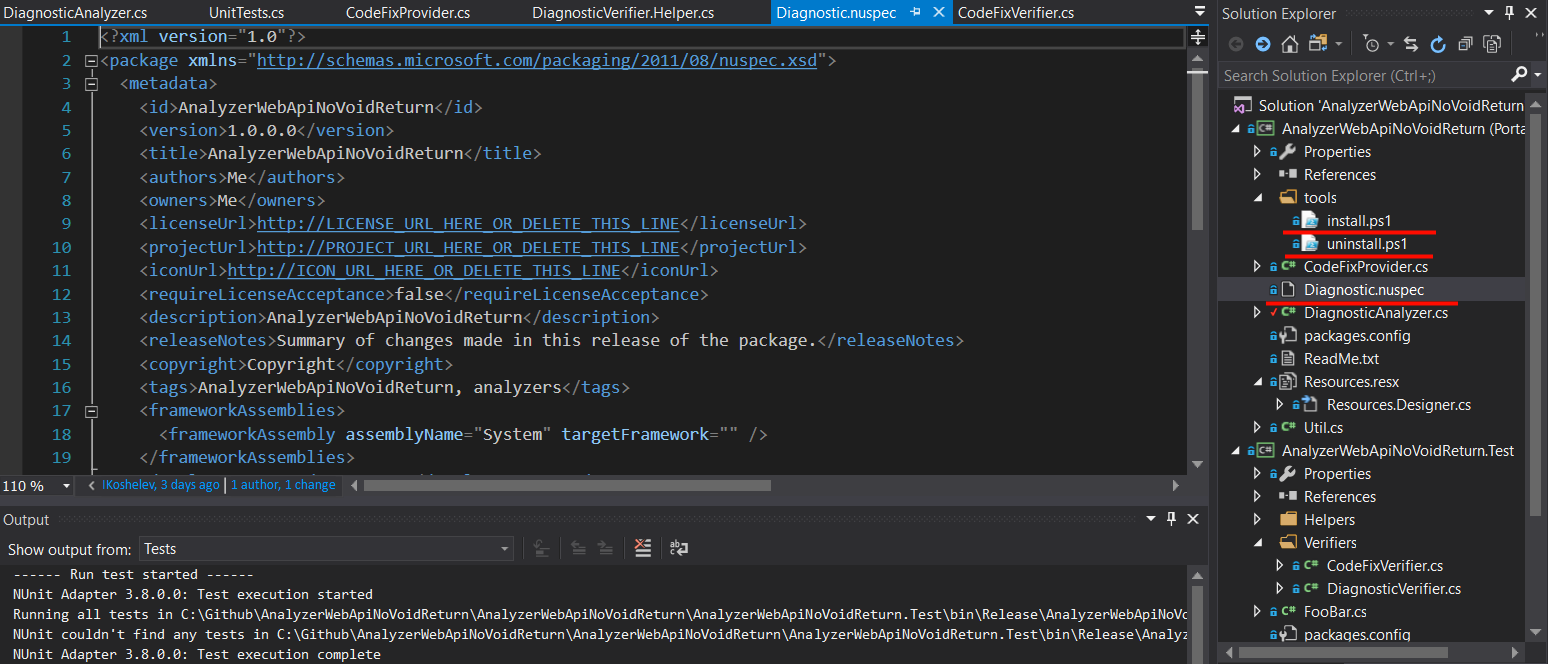
If you need help using nuspec to create a package, here is a good article.
Meanwhile, if you go to AnalyzerWebApiNoVoidReturn\bin\Release, you will find the version of your analyzer from the latest release build packed and ready for use.
For a quick test, I have a package source set up pointing to a sub-folder in my “downloads” folder. With this setup, any .nuspec file in that folder will be available for installation.
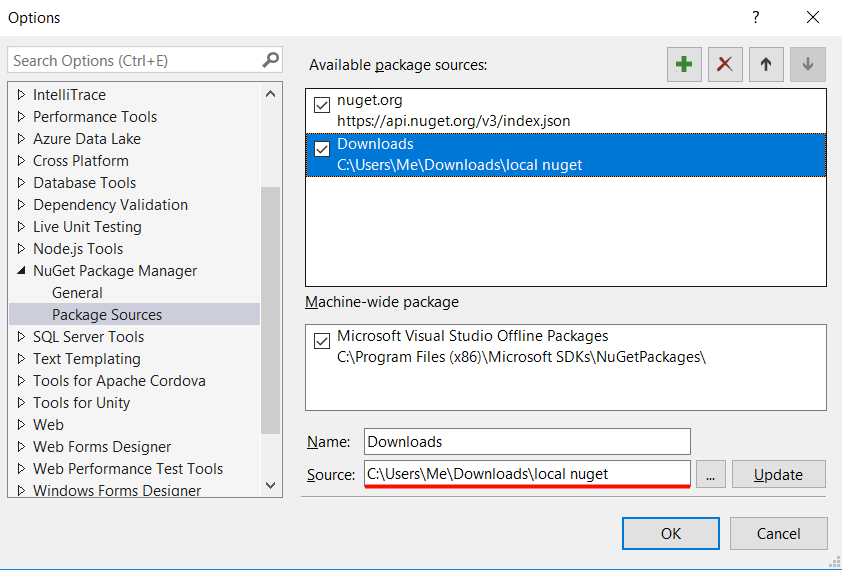
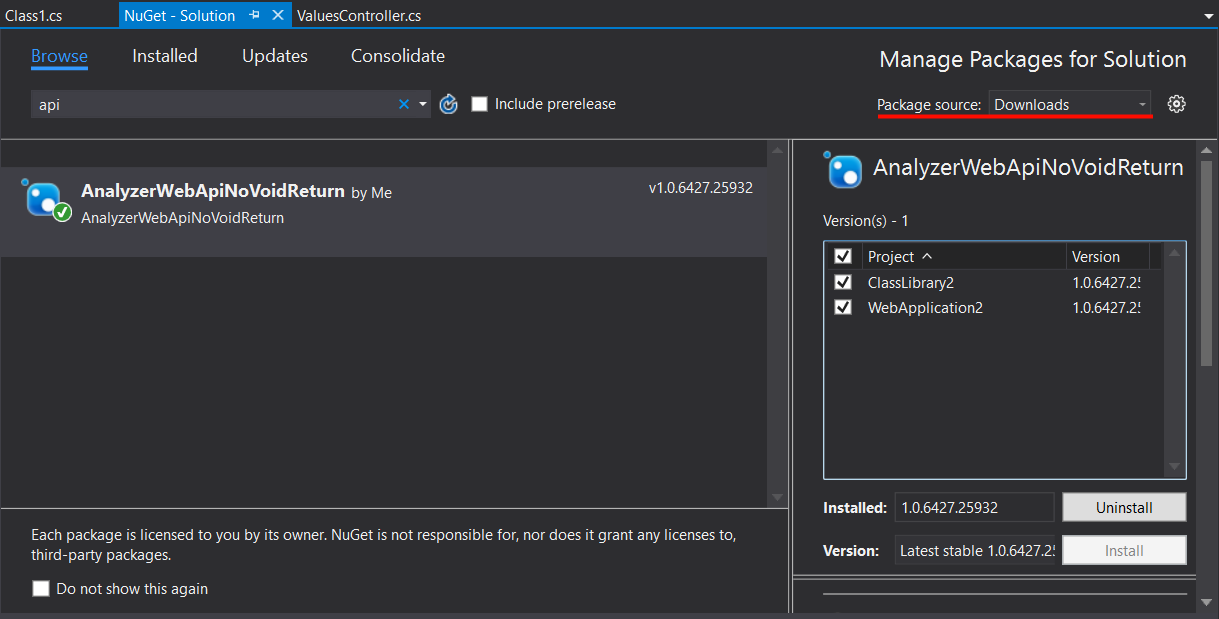
Congratulations, our analyzer is done and saves us time every day!