Roslyn compiler platform is among the best things that happened to .NET in the previous decade. 10 years ago static code analysis was reserved for teams of highly dedicated programmers who spent hundreds of hours studying C# compilation process and intermediary models that stood between a programs text and resulting byte-code. Thanks to their contribution and great work done by the .NET team, today we can achieve the same result in mere hours with a comprehensive and user-friendly API gateway into the compilation process. This article will show you the easiest, yet very practical form of static code analysis with Roslyn, something that takes under an hour to use: Workspaces.
Roslyn is at the core of modern C# IDEs. When you click a screwdriver icon in Visual Studio and choose a quick refactoring - that's a Roslyn "code fix". When during compilation a 3-rd party library gives you a warning concerning how your code is using its API - that's Roslyn "analyzer".
🔗 Prerequisites
Official documentation is available in SDK overview, but it is more of a comprehensive reference than practical starter guide. If you are not familiar with Syntax Graph aka "tokenization" and Symbol Graph aka "binding" stages of compilation process, one of my previous articles has a concentrated explanation. Make sure you install visualizer tool, it is available as Visual Studio extension ( via Visual Studio Installer), or as part of LINQPad free version.
The solution we will be working with is on GitHub. It consists of two projects: Roslyn, which contains our analysis code and TestSubject - a synthetic code-base on which our queries will run. TestSubject emulates a situation where code was carelessly duplicated instead of keeping things DRY and as a result is has become hard to maintain some of our logics when requirements change. For example, the logic below is duplicated in many places, albeit with slightly different implementations and often as part of much bigger queries.
var isUserInvalid = userDto.IsSuspended
|| userDto.ActiveRole == null
|| !(userDto.CredentialsStartDate < DateTime.Now && DateTime.Now < userDto.CredentialsEndDate);
if (isUserInvalid)
{
return;
}
Example of duplication:
if (user.IsSuspended || user.ActiveRole != Roles.Admin
|| user.CredentialsStartDate > DateTime.Now || DateTime.Now > user.CredentialsEndDate)
{
return;
}
In a real-world code-base, each property used in those expressions would also be used across hundreds of other places, so sifting through them manually via "find all references" is not ideal. Plus, less obvious logic duplication is all over the place, so we need an automated query that will find duplication for us.
🔗 Workspace
Let's take a look at Program.cs of Roslyn project. First we load our TestSubject project into a Workspace and prepare a full list of ALL of it`s nodes. This part will largely be identical whatever you do.
using var workspace = MSBuildWorkspace.Create();
var project = await workspace.OpenProjectAsync(@"..\..\..\..\TestSubject\TestSubject.csproj");
IEnumerable<(Document document, SyntaxNode node)> allNodes =
await GetAllNodeOfAllDocuments(project.Documents.ToArray());
var compilation = new Lazy<Task<Compilation>>(() => project.GetCompilationAsync());
🔗 Finding nodes of interest
Code relevant to current article is in RunQueryExample function. We run a query function to examine each node individually (yes, that's every single node of our TestSubjects code) and choose nodes that are of interest to us. We gradually probe the structure of syntax sub-tree rooted at this particular node (it's descendants), making sure it represents the kind of code we are looking for. If we discover, that a given sub-tree is not what we are looking for - we return null. If we get to the end of our query function - this means we have found a node we were looking for. As we go, we also gather meta-information that will be useful during next step, like a list of all descendant MemberAccessExpressions, and information that will help us locate this node later - its containing type and method name.
var contextsOfInterest = await GetContextsOfInterest(allNodes, async (x) =>
{
var partsOfLogicalExpression = new[]
{
SyntaxKind.LogicalOrExpression,
SyntaxKind.LogicalAndExpression,
SyntaxKind.LogicalNotExpression,
SyntaxKind.ParenthesizedExpression
};
var (document, node) = x;
if (false == node.IsKindAny(partsOfLogicalExpression)) { return null; }
// Check if node is nested within a bigger logical expression.
// We are only interested in 'tips', NOT in nested nodes
var isNestedWithinAnotherNodeOfInterest = node.Ancestors()
.TakeWhile(x => x.IsKindAny(nodesOfInterest))
.Any();
if (isNestedWithinAnotherNodeOfInterest) { return null; }
// We are looking for complex expressions with multiple
// || or && operators
var containedLogicalOperatorsCount = node.DescendantNodesAndSelf()
.Count(x => x.IsKindAny(SyntaxKind.LogicalOrExpression,
SyntaxKind.LogicalAndExpression));
if (containedLogicalOperatorsCount < 2) { return null; }
// By this point we know, that current examined node is of interest
// to us, and all that is left is to prepare relevant
// metadata for future analysis.
var declaringMethodName = node.Ancestors()
.OfType<MethodDeclarationSyntax>()
.FirstOrDefault()
?.Identifier.Text;
var declaringTypeName = node.Ancestors()
.OfType<TypeDeclarationSyntax>()
.FirstOrDefault()
?.Identifier.Text;
var model = (await compilation.Value).GetSemanticModel(
await document.GetSyntaxTreeAsync());
// We prepare list of SimpleMemberAccessExpression nodes contained
// within the syntax sub-tree rooted at current node (it's descendants),
// the list will be used in similarity analysis down the road.
// We are looking for expressions like 'x.y',
// this code will be represented by a SimpleMemberAccessExpression
// having Expression property of IdentifierName.
// We will get the 'x.y' part of code like
// x.y
// x.y.z.c
// x.y.Contains(...)
(string typeName, string memberName)[] memberAccessExpressions
= node
.DescendantNodesAndSelf()
.Where(x => x.IsKind(SyntaxKind.SimpleMemberAccessExpression))
.OfType<MemberAccessExpressionSyntax>()
// Note, that before we were working just with syntax.
// Here we are using semantic model of our code to get
// information about actual type contained in a given variable.
.Where(x => x.Expression.IsKind(SyntaxKind.IdentifierName))
.Select(x =>
(
typeName: model.GetTypeInfo(x.Expression).Type?.Name,
memberName: x.Name.Identifier.Text
))
.ToArray();
var fullText = node.GetText().ToString();
var condensedText = whitespaceRemover.Replace(fullText, "");
return new LogicalExpressionContext(
node,
memberAccessExpressions,
declaringMethodName,
declaringTypeName,
fullText,
condensedText);
});
How do we go about writing the function above from scratch? First we find a few places that are representative of the kind of code we would like to find and examine them in syntax visualizer.
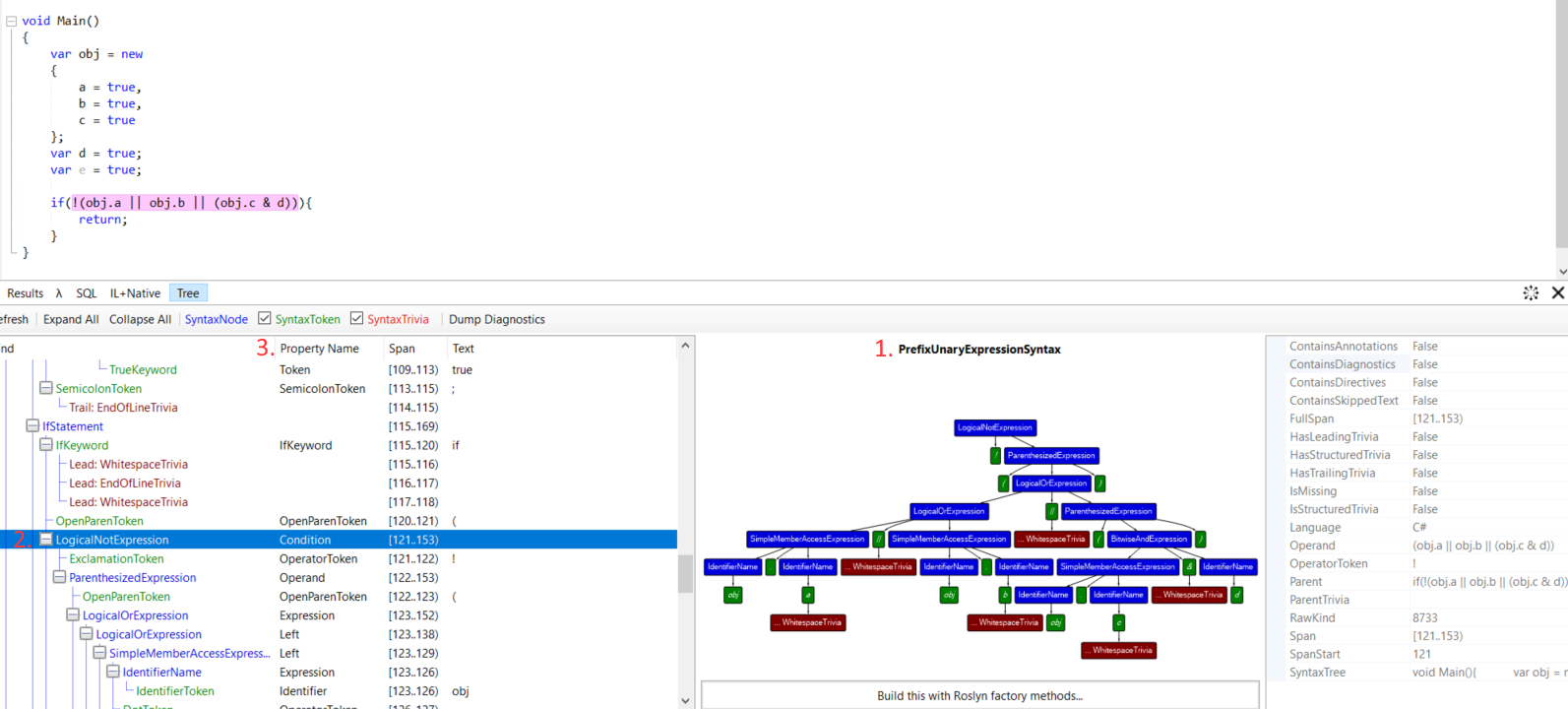
You should examine at-least 3 different places containing code that you would like to find. There are a lot of possibilities when it comes to C# syntax and you will never remember all of them. Expect to refine the query at-least twice after you examine its results, and likely a lot more. Here are a couple of things to note with syntax visualizer.
1. is the name of the C# class that represents a given node, the class that you can cast it to like var memberAccess = x as MemberAccessExpressionSyntax;.
2. is the Kind of the node. It is more specific than class from 1., for example, instance of BinaryExpressionSyntax can have a Kind of LogicalOrExpression, LogicalAndExpression and so on.
3. is the name of shorthand property on Parent node that contains current node. All nodes form a graph that can be traversed with just the Parent and Children properties from the base class SyntaxNode. But more concrete classes also provide you with shorthand properties for the key parts. For example, MemberAccessExpressionSyntax that represents piece of code like obj.a will have property Expression pointing to the obj part of the syntax tree and property Name pointing to a.
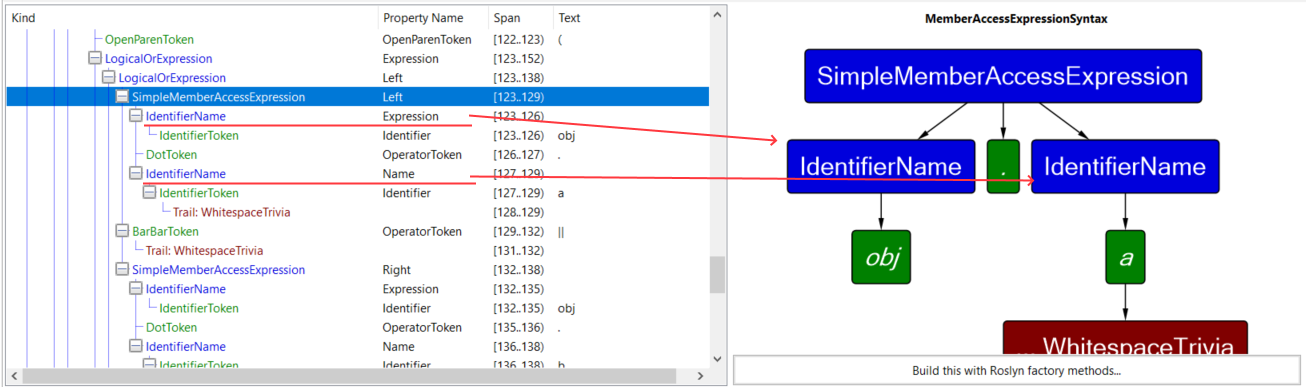
Inside the queries we are making, we will often use the following pattern:
var memberAccess = x as MemberAccessExpressionSyntax;
if(memberAccess == null) { return null; }
var memberSource = memberAccess.Expression as IdentifierNameSyntax;
if(memberSource == null) { return null; }
// more checks....
When creating our query function, our goal is to gradually add examinations of the sub-tree through an iterative process. We start with a simple Kind check on the current node, then write a few lines to check if it contains or does not contain specific descendants, run the query to check the result, then add next check. Don't worry about efficiency here, concentrate on correctness and comprehensiveness. Workspaces are incredibly fast, compilation and analysis of a 100k lines project often takes us less than 2 minutes, so speed should not be a problem. It's also not likely that you will run a given query more than 20 times ever, so remember XKCD "Is It Worth the Time?" Once we've finished the query, we now have a list of nodes that passed your criteria and their contexts. Please note, that we can get arbitrarily complex in our analyses. Any condition that you can formulate - you can likely check.
🔗 Comparing nodes to each other
It is quite possible that query on it's own is enough to give us what we need. But currently we are looking for duplication, so we will have to compare nodes against each other. Searching for duplication requires 'fuzzy' comparison. There are several choices here. Choice number one is to normalize text representation of each node by removing all the trivia like whitespace and calculate Levenshtein distance between texts. Here is a good implementation of Levenshtein distance algorithm for .NET. In a big codebase where people liked to ctrl+c ctrl+v code, we can get surprisingly good results by simply looking at nodes who's Levenshtein distance is under 25% of their overall text size, i.e. distance of < 32 for nodes of size > 128 chars. I also suspect that Graph Edit Distance algorithms could work nicely here, but did not yet have time to fully look into it.
For current case, however, it makes more sense to compare member access, so we use all member access expressions that we found within a given node to look for places which access at least 3 or the same members. This is a place where you will have to play around with the thresholds, but typically 3 or 4 matches are a good starting point.
// You will get some duplication: when context A has similar context B -
// then context B will also be recorded to have similar context A.
// This can be removed, but it may be a good idea to leave it there during exploration phase.
var similarContexts = contextsOfInterest.Select(context =>
{
(Context<LogicalExpressionContext> context, int sameMembersAccessCount)[]
contextsWithSimilarMemberAccessed =
contextsOfInterest
.Where(x => x != context)
.Select(x => (
context: x,
sameMembersAccessCount: x.meta.memberAccessesInvolved
.Intersect(context.meta.memberAccessesInvolved)
.Count()))
// at least 3 of the same members accessed
.Where(x => x.sameMembersAccessCount >= 3)
.OrderByDescending(x => x.sameMembersAccessCount)
.ToArray();
return (context, similarContexts: contextsWithSimilarMemberAccessed);
})
.Where(x => x.similarContexts.Count() > 0)
.OrderByDescending(x => x.similarContexts.FirstOrDefault().sameMembersAccessCount)
.ToArray();
In general, I found that the pattern of "find well definable bits of similarity and look for nodes that have 3+ in common" works good. "Well definable" means workings with things that can't change from case to case, like type and member names, as opposed to arbitrary things like parameter or variable names.
Finally, we prepare a text report with the findings of our query.
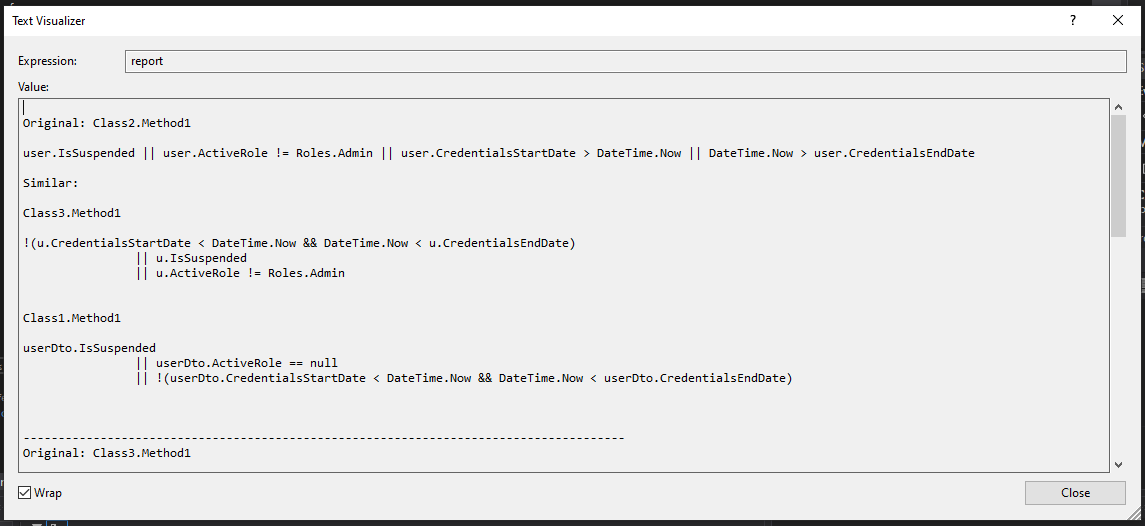
This demonstrates the power of Roslyn analysis as opposed to, for example, just Regexs. Our query picked up similarities despite different variable names, different formatting, logical operation sequences and operators. A query like this normally takes under an hour to get from inception to producing actionable results.
This article has shown you how easy it is to run custom powerful static analysis in .NET now. Checkout part 2 which uses DocumentEditor to make changes in our code-base.
