Working on Roslyn extensions is a bit different from day-to-day enterprise development. You have to get used to working with immutable trees of data representing everything in a solution. You also have to keep in your head, which parts of code map to nodes, which to tokens and other code tree representation subtleties. This article will teach you a few things to get results faster and alleviate the tedium.
Most tips we will discuss can be seen in action in https://github.com/IKoshelev/Roslyn.AutoLogging project.
With great power comes great responsibility...
C# is one of the richest programming languages out there feature-wise. Normally this is a boon, but for an extension developer can be a great burden to bear.
For example, you would not expect there to be a big difference between field and auto property declaration? After all, both typically start with an access modifier keyword followed by a Type identifier, and a name. Properties than also have a getter / setter section. So you would expect field declaration to be just like a property declaration minus the getter / setter part code-tree-wise.
class Foo
{
int a;
int B { get; set; }
}
Alas, there is a possibility which you almost never see in enterprise code, but C# supports: you can declare several fields of the same Type in 1 line by specifying their identifiers separated by a coma.
class Foo
{
int a, b, c;
int D { get; set; }
}
The same is possible with local vars, and, as you can imagine, the resulting code-tree is quite different from the one you get with a property. This trick is, this applies even when you only declare a single field.
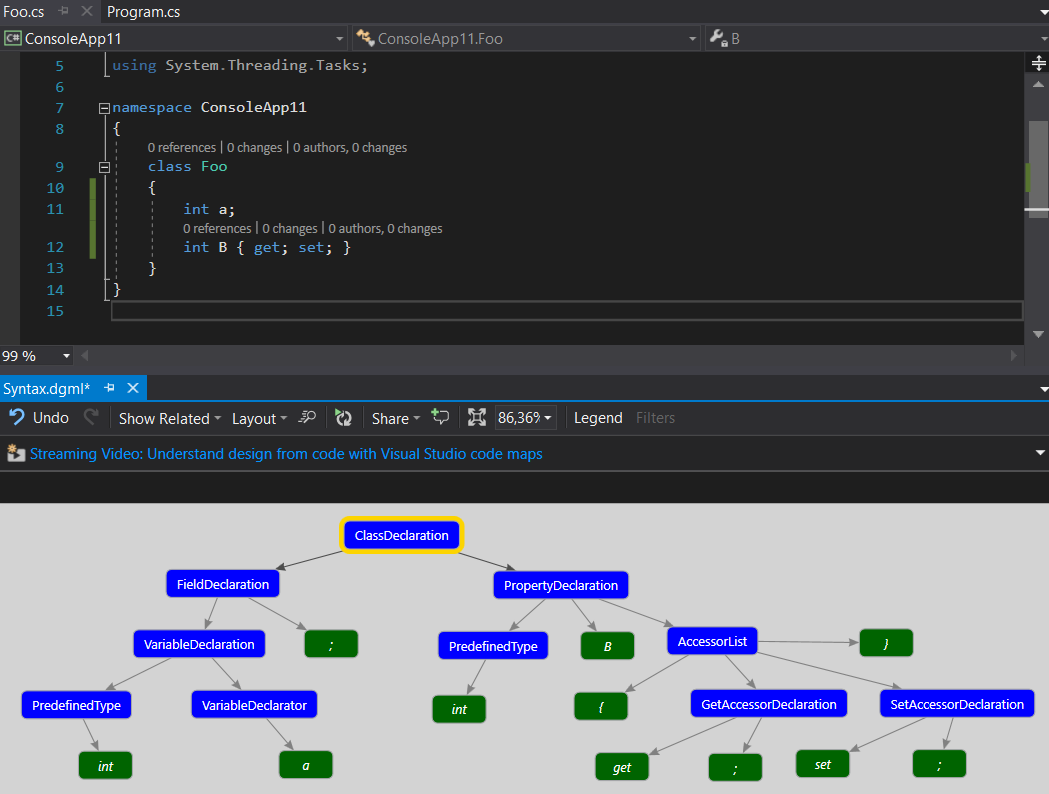
Notice, how PropertyDeclaration node directly contains identifier token B as child, but FieldDeclaration node contains a child FieldDeclaratorNode and only that one contains identifier token a (and could well contain other identifier tokens for multiple fields declaration).
... but don't stretch yourself too thin
Creating tools for C# means constantly asking yourself, what other possible language feature / cases did I not account for? It is also very important to know, when to stop this. If handling a corner case will take you multiple hours to implement, but the chances your users will actually encounter this case are small – don’t bother (until someone actually comes complaining). Stick to the cases that made you actually consider making an extension in the first place.
Same goes for "nice to have" finishing touches. For example, Roslyn formatter (discussed later) does not know how to format dictionary literals. You could spend X hours developing and testing a decent formatter, but how much time would it save compared to manual format by resident dev using your extension? 5-10 seconds on a typical usage. That means, this investment will only return itself after maybe 360 uses. Ask yourself, is it worth it?
It is also good to know, where to make a transition from Roslyn world to C# world. If something can later be handled inside of projects itself with reflection or by Roslyn via symbol analysis – use reflection, at least until you have a definite proof that investing time into more thorough Roslyn analysis makes sense. Don’t go for too much work upfront – make a minimum shippable prototype solving the most frequent / painfull case and introduce your team to it.
Taking into account the above, do consider open-sourcing your work. And you can always accept a pull-request for a feature someone needs enough to invest into ;-).
Skipping syntax tree and working with raw text
Extensions are all about modifying code trees to automate routine operations and fixes. Diagnostics typically start by examining symbol graph to identify deeper problems with code, but then also need to provide a quick fix (and provide one they should – a custom compilation error without an offer of quick fix is VERY annoying to most programmers). This means more code tree modification. Since we are talking immutable trees here, modification really means creating a new sub-tree and substituting an existing one for it.
In previous articles we have already seen how Roslyn Quoter https://roslynquoter.azurewebsites.net/ helps us by taking in a piece of C# code and providing us with code to create an equivalent syntax tree. What’s nice is that we can do the same thing directly inside our extensions. Remember initial code text and parsed syntax tree have a 1-1 mirror relationship in Roslyn.
SyntaxFactory type provides you with a handful of methods called ParseStatement, ParseExpressionTree, ParseX, which accept a string containing some code and return to you its corresponding syntax tree. Oftentimes, the easiest way to create a new tree is convert pieces of old tree into their corresponding text, plug that text into a given textual template and then parse a syntax tree from it.
Lets say, we wanted to log all arguments passed to a method during invocation, like this:
// given this methos signature
void TestMethod(int a, FooBar b)
{
// we would like to insert logging as follows:
_log.LogMethodEntry(nameof(TestMethod), new Dictionary>string, object<()
{
{nameof(a),a},
{nameof(b),b}
});
...
We will use the following code:
private static StatementSyntax GetLoggingStatementWithDictionaryState(
MethodDeclarationSyntax methodDecl,
string logMethodName,
params SyntaxToken[] stateToLog)
{
// TrimmedText() extension method get the textual
// equivalent of a given Token\Node with whitespace trimmed
var methodName = methodDecl.Identifier.TrimmedText();
string logInvocationStr =
$@"{LoggerClassName}.{logMethodName}(nameof({methodName})";
if (stateToLog.Any())
{
var dictionaryLiteralParameters = stateToLog
.Select(x => x.TrimmedText())
.Select(x => $"{{nameof({x}),{x}}}");
var dictionaryLiteralParametersStr =
String.Join(",\r\n", dictionaryLiteralParameters);
logInvocationStr +=
$@", new Dictionary>string,object<()
{{
{dictionaryLiteralParametersStr}
}});
";
}
else
{
logInvocationStr += ");";
}
// parse resulting code into syntax tree
var statement = SF.ParseStatement(logInvocationStr);
return statement;
}
Making multiple cumulative replacements in code
Sometimes you need to identify a number of places in a given code that need to change. Changes are made one by one, but there is a problem. As soon as you make a change you get a new version of your entire code tree, which does not contain any code pieces you’ve identified previously, it only contains their equivalents. This means you have to relocate next change site, accounting for all places you’ve already modified. This is not a trivial task. Luckily for us, we can track any nodes we have located before first change and later easily find their corresponding nodes in new trees:
private static MethodDeclarationSyntax AddDeclarationAssignementLogging(
MethodDeclarationSyntax methodDecl)
{
var declarations = GetRelevantDeclarations(methodDecl);
// we mark nodes that we want to keep track of
var newMethod = methodDecl.TrackNodes(declarations);
foreach (var declaration in declarations)
{
// at the start of each iteration, we find the relevant node
// in the current version of our graph
var assignemntCurrent = newMethod.GetCurrentNode(declaration);
// produce additional code that we want to insert
var declarationSyntax = assignemntCurrent.Parent
as LocalDeclarationStatementSyntax;
if(declarationSyntax == null)
{
continue;
}
var block = assignemntCurrent.FirstAncestorOrSelf<BlockSyntax>();
var statements = block.Statements;
var declarator = declaration
.DescendantNodes()
.OfType<VariableDeclaratorSyntax>()
.Single();
var logExpression = GetLoggingStatementWithSingleStateWithName(
methodDecl,
LogAssignmentName,
declarator.Identifier);
logExpression = logExpression.WithTrailingTrivia(SF.LineFeed);
var declarationIndex = statements.IndexOf(declarationSyntax);
// insert it
statements = statements.Insert(declarationIndex + 1, logExpression);
// after the following line, newMethod contains a wholly new
// syntax tree, so we will need to get 'current' equivalent
// of next node from it
newMethod = newMethod.ReplaceNode(block, SF.Block(statements));
}
return newMethod;
}
Auto-formatting newly modified code
Producing code trees that compile correctly is a hard enough task on its own, without having to also think about how pretty they are, does the indentation match? Luckily, Roslyn offers us a way to auto-format code fragments:
private static MethodDeclarationSyntax Formatted( Workspace workspace,
MethodDeclarationSyntax newMethod,
CancellationToken cancellationToken)
{
newMethod = newMethod.WithAdditionalAnnotations(Formatter.Annotation);
var formattedMethod = Formatter.Format(newMethod,
Formatter.Annotation,
workspace,
workspace.Options,
cancellationToken)
as MethodDeclarationSyntax;
return formattedMethod;
}
Which version of Roslyn libraries to use?
Extensions using Roslyn have to choose the version of libraries they target, ranging from 1.0 to 2.4 at the time this article is written. The greater the version, the more features you are able to use. This also includes language features, for example, there is no SyntaxKind.LocalFunctionStatement (appeared in C# 7) prior to version 2.0. As far as I remember, .NET Core is only supported in version 2.0 and later, prior to that libraries target .NET Portable. So, why not always target the latest and greatest? Because each version of Visual Studio only support a given version of Roslyn. For example, Visual Studio 2015 does not support Roslyn extension libraries of version 2.X, and even for 1.34 your users would need the latest update of VS 2015.
This means you should try to use the lowest possible version you can get away with. This is especially relevant when choosing 1.X versus 2.X, because of Core support. From experience, enterprise developer teams are widely different when it comes to choosing a version of VS they use. They are limited by budgets to buy the newest version; older products they have to support which need older version of VS; policy makers which govern what the whole organization uses (oh, that’s the most painful one usually!); finally, they may simply not want to switch to a new version when the old one has proven itself in battle (and this IS a wise choice, as the latest VS 2017 is still somewhat unstable for my current teams).
So, how do you know, which version of libraries is supported by the VS version your team uses? You can check this out at https://github.com/dotnet/roslyn/releases
At the time this article is written, it is very likely that you may need to support two version of the same library – one portable and one targeting .NET Standard for two identical VSIXs targeting VS 2015 and VS 2017. While tackling this problem, I found it easiest to start working with .NET Core version targeting Roslyn 2.X, develop and unit test it, than, once code is more or less final, create a separate library targeting .NET Portable library, copy the needed files into it as ‘references’ and use preprocessor directives to make the same file compile for both versions 1.X and 2.X.
...
.Any(node => node.Kind().Fits(
#if PCL
#else
// code inside this section
// will be removed for Portable Class Library
// compilation
SyntaxKind.DefaultLiteralExpression,
#endif
SyntaxKind.NumericLiteralToken,
SyntaxKind.CharacterLiteralToken,
SyntaxKind.StringLiteralToken,
...)
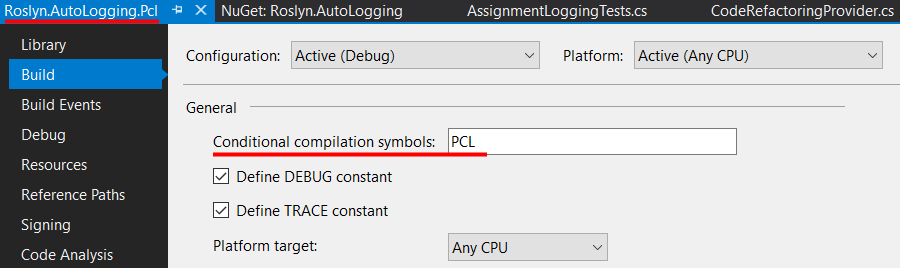
BTW, you may need to edit its .csproj file of your portable library, making sure it targets the following profile and framework:
<TargetFrameworkProfile>Profile7</TargetFrameworkProfile>
<TargetFrameworkVersion>v4.5</TargetFrameworkVersion>
Hopefully, tips in this article will make Roslyn extensions development fast and easy for you, since they really open up the next level of enterprise development. If you want more inspiration, along with blueprints for how to do stuff, consider checking out the follwoing fine projects on Github. Whatever you need to acomplish, chances are there will be a refactoring \ diagnostics which is very close to your case and will fit your needs with minimum modification.
https://github.com/JosefPihrt/Roslynator
